Query Data in a Relational Model
Storing our data is great, but the best data model would be useless without the ability to query the data our app requires. So, how does information get retrieved in a relational model compared to a graph model?
In a relational model, tables are stored in files. To support the sample social media app described in this tutorial, you would need four files: People, Posts, Comments, and Likes.

When you request data from a file, one of two things happens: either a table scan takes place or an index is invoked. A table scan happens when filtering upon data that is not indexed. To find this data, the whole file must be read until the data is found or the end of the file is reached. In our example app we have a post titled, “Ice Cream?”. If the title is not indexed, every post in the file would need to be read until the database finds the post entitled, “Ice Cream?”. This method would be like reading the entire dictionary to find the definition of a single word: very time-consuming. This process could be optimized by creating an index on the post’s title column. Using an index speeds up searches for data, but it can still be time-consuming.
What is an index?
An index is an algorithm used to find the location of data. Instead of scanning an entire file looking for a piece of data, an index is used to aggregate the data into “chunks” and then create a decision tree pointing to the individual chunks of data. Such a decision tree could look like the following:
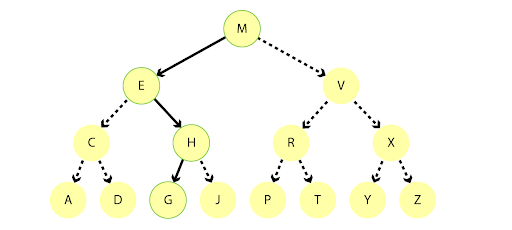
Relational data models rely heavily on indexes to quickly find the requested data. Because the data required to answer a single question will usually live in multiple tables, you must use multiple indexes each time that related data is joined together. And because you can’t index every column, some types of queries won’t benefit from indexing.
How data is joined in a relational model
In a relational model, the request’s response must be returned as a single
table consisting of columns and rows. To form this single table response, data
from multiple tables must be joined together. In our app example, we found the
post entitled “Ice Cream?” and also found the comments, “Yes!”, “When?”, and
“After Lunch”. Each of these comments also has a corresponding author: Mother,
Child, and Father. Because there is only one post as the root of the
join, the post is duplicated to join to each comment.
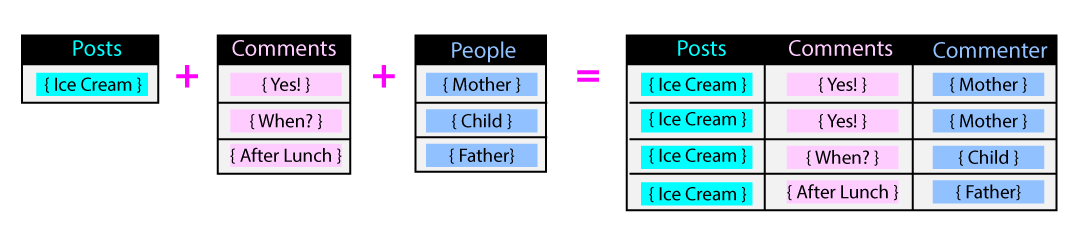
Flattening query results can lead to many duplicate rows. Consider the case
where you also want to query which people liked the comments on this example
post. This query requires mapping a many-to-many relationship, which invokes two
additional index searches to get the list of likes by person.
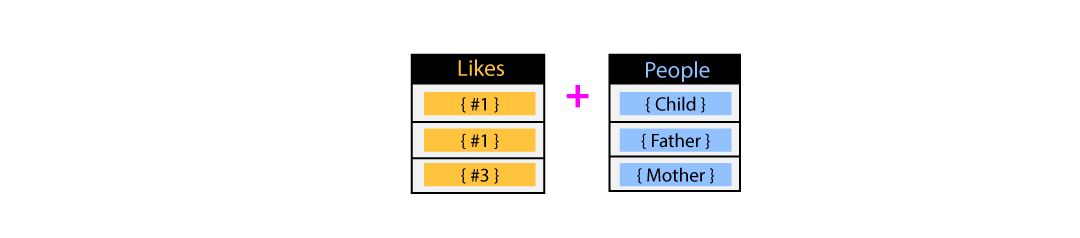
Joining all of this together would form a single table containing many
duplicates: duplicate posts and duplicate comments. Another side effect of
this response approach is that it is likely that empty data will exist in the
response.
In the next section, you will see that querying a graph data model avoids the issues that you would face when querying a relational data model.