GraphQL Schema
In this section, you’ll learn about how to translate the schema design to the GraphQL SDL (Schema Definition Language).
App Schema
In the schema design section, you saw the following sketch of a graph schema for
the example message board app:
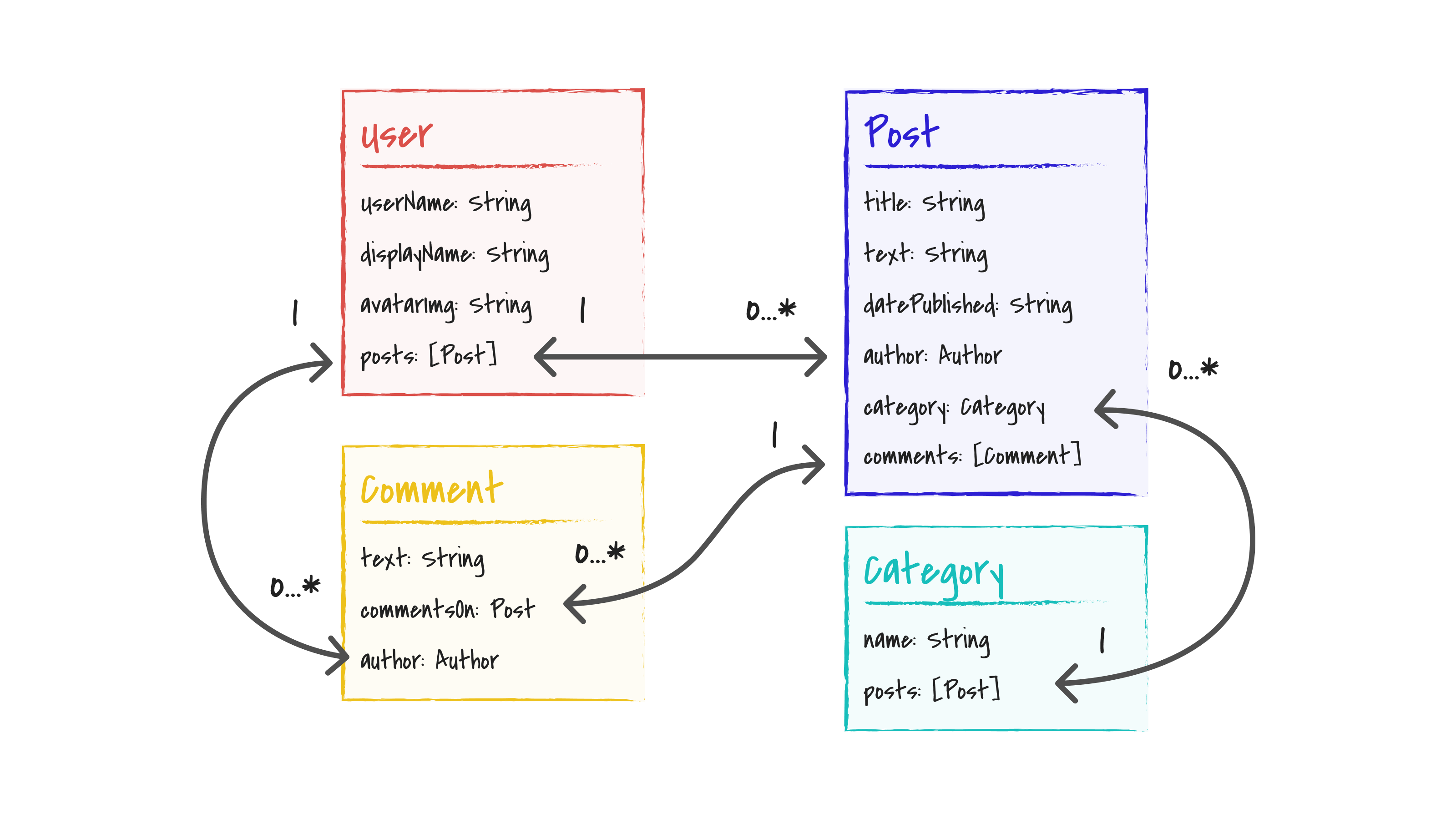
data model sketch
Using the GraphQL SDL, Dgraph Cloud generates a running GraphQL API from the description of a schema as GraphQL types. There are two different aspects of a GraphQL schema:
- Type Definitions: these define the things included in a graph and the shape of the graph. In this tutorial, you will derive the type definitions from the sketch shown above.
- Operations: these define what you can do in the graph using the API, like the search and traversal examples in the previous section. Initially, Dgraph Cloud will generate create, read, update and destroy (CRUD) operations for your API. Later in this the tutorial, you’ll learn how to define other operations for your schema.
You’ll start by learning about the GraphQL SDL and then translate the app schema sketch into GraphQL SDL.
GraphQL Schema
The input schema to Dgraph Cloud is a GraphQL schema fragment that contains type definitions. Dgraph Cloud builds a GraphQL API from those definitions.
This input schema can contain types, search directives, IDs, and relationships.
Types
Dgraph Cloud supports pre-defined scalar types (including Int, String, Float and DateTime) and a schema can define any number of other types. For example, you can start to define the Post type in the GraphQL SDL by translating the following from the app schema sketch shown above:
type Post {
title: String
text: String
datePublished: DateTime
author: User
...
}
A type TypeName { ... } definition defines a kind of node in your graph. In this case, Post nodes. It also gives those nodes what GraphQL calls fields, which define a node’s data values. Those fields can be scalar values: in this case a title, text and datePublished. They can also be links to other nodes: in this case the author edge must link to a node of type User.
Edges in the graph can be either singular or multiple. If a field is a name and a type, like author: User, then a post can have a single author edge. If a field uses the list notation
with square brackets (for example comments: [Comment]), then a post can have
multiple comments edges.
GraphQL allows the schema to mark some fields as required. For example, you
might decide that all users must have a username, but that users aren’t required
to set a preferred display name. If the display name is null, your app can choose
to display the username instead. In GraphQL, required fields are marked using
an exclamation mark (!) annotation after the field’s type.
So, to guarantee that username will never be null, but allow displayName to
be null, you would define the User type as follows in your schema:
type User {
username: String!
displayName: String
...
}
This annotation carries over to lists, so comments: [Comment] would allow both a null list and a list with some nulls in it, while comments: [Comment!]! will never allow either a null comments list, nor will it allow a list with that contains any null values. The ! notation lets your UI code make some simplifying assumptions about the data that the API returns, reducing the need for client-side error handling.
Search
The GraphQL SDL syntax shown above describes your types and the shape of your application data graph, and you can start to make a pretty faithful translation of the types in your schema design. However, there’s a bit more that you’ll need in the API for this app.
As well as the shape of the graph, you can use GraphQL directives to tell Dgraph Cloud some more about how to interpret the graph and what features you’d like in the GraphQL API. Dgraph Cloud uses this information to specialize the GraphQL API to fit the requirements of your app.
For example, with just the type definition, Dgraph Cloud doesn’t know what kinds of search you need your API to support. Adding the @search directive to the schema tells Dgraph Cloud about the search needed. The following schema example shows two ways to add search directives.
type Post {
...
title: String! @search(by: [term])
text: String! @search(by: [fulltext])
...
}
These search directives tell Dgraph Cloud that you want your API support searching posts by title using terms, and searching post text using full-text search. This syntax supports searches like “all the posts with GraphQL in the title” and broader search-engine style searches like “all the posts about developing GraphQL apps”.
IDs
Dgraph Cloud supports two types of identifiers: an ID type that gives
auto-generated 64-bit IDs, and an @id directive that allows external IDs to be
used for IDs.
ID and @id have different purposes, as illustrated by their use in this app:
IDis best for things like posts that need a uniquely-generated ID.@idis best for types, likeUser, where the ID (their username) is supplied by the user.
type Post {
id: ID!
...
}
type User {
username: String! @id
...
}
A post’s id: ID gives each post an auto-generated ID. For users, you’ll need a
bit more. The username field should be unique; in fact, it should be the id
for a user. Adding the @id directive like username: String! @id tells Dgraph Cloud
GraphQL that username should be a unique ID for the User type. Dgraph Cloud
GraphQL will then generate the GraphQL API such that username is treated as an
ID, and ensure that usernames are unique.
Relationships
A critical part of understanding GraphQL is learning how it handles
relationships. A GraphQL schema based around types like those in the following
example schema types specifies that an author has some posts and each post has
an author, but the schema doesn’t connect them as a two-way edge in the graph.
So in this case, your app can’t assume that the posts it can reach from a
particular author all have that author as the value of their author edge.
type User {
...
posts: [Post!]!
}
type Post {
...
author: User!
}
GraphQL schemas are always under-specified in this way. It’s left up to the documentation and implementation to make a two-way connection, if it exists. There might be multiple connections between two types; for example, an author might also be linked to the the posts they have commented on. So, it makes sense that you need something other than just the types as defined above to specify two-way edges.
With Dgraph Cloud you can specify two-way edges by adding the @hasInverse
directive. Two-way edges help your app to untangle situations where types have
multiple edges. For example, you might need to make sure that the relationship
between the posts that a user has authored and the ones they’ve liked are linked
correctly.
type User {
...
posts: [Post!]!
liked: [Post!]!
}
type Post {
...
author: User! @hasInverse(field: posts)
likedBy: [User!]! @hasInverse(field: liked)
}
The @hasInverse directive is only needed on one end of a two-way edge, but you
can add it at both ends if that adds clarity to your documentation and makes
your schema more “human-readable”.
Final schema
Working through the four types in the schema sketch, and then adding @search
and @hasInverse directives, yields the following schema for your app.
type User {
username: String! @id
displayName: String
avatarImg: String
posts: [Post!]
comments: [Comment!]
}
type Post {
id: ID!
title: String! @search(by: [term])
text: String! @search(by: [fulltext])
tags: String @search(by: [term])
datePublished: DateTime
author: User! @hasInverse(field: posts)
category: Category! @hasInverse(field: posts)
comments: [Comment!]
}
type Comment {
id: ID!
text: String!
commentsOn: Post! @hasInverse(field: comments)
author: User! @hasInverse(field: comments)
}
type Category {
id: ID!
name: String! @search(by: [term])
posts: [Post!]
}
Dgraph Cloud is built to allow for iteration of your schema. I’m sure you’ve picked up things that could be added to enhance this example app, i.e., the ability to add up and down votes, or to add “likes” to posts. In this tutorial, we discuss adding new features using an iterative approach. This approach is the same one that you take when working on your own project: start by building a minimal working version, and then iterate from there.
Some iterations, such as adding likes, will just require a schema change; Dgraph Cloud
GraphQL will update very rapidly to adjust to this change. Some iterations, such
as adding a @search directive to comments, can be done by extending the schema.
This will cause Dgraph Cloud to index the new data and then update the API.
Very large iterations, such as extending the model to include a history of edits
on a post, might require a data migration.